Solution

Autonomous grasping of orange from any position |

Autonomous grasping of orange from plant |
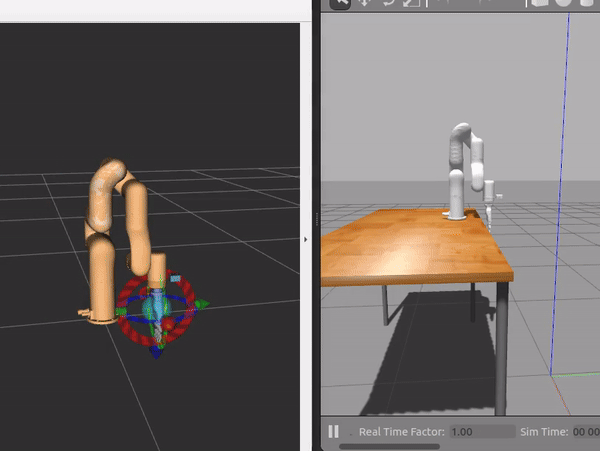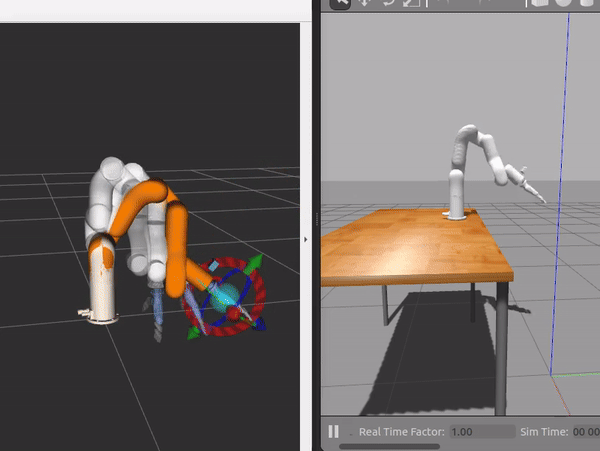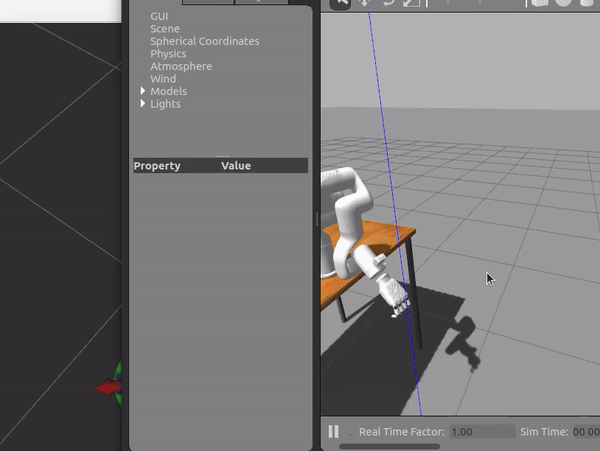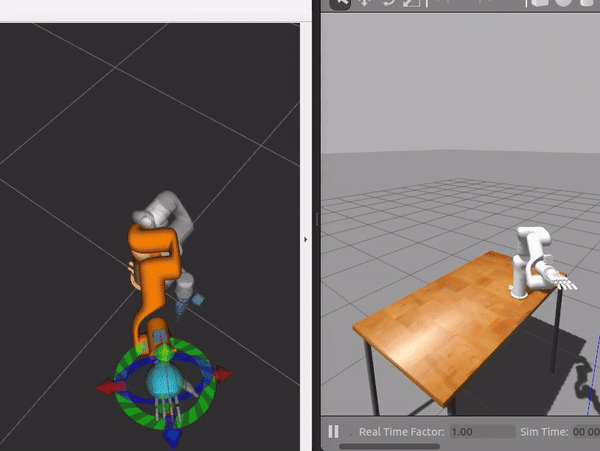
Motion planning in simulation |
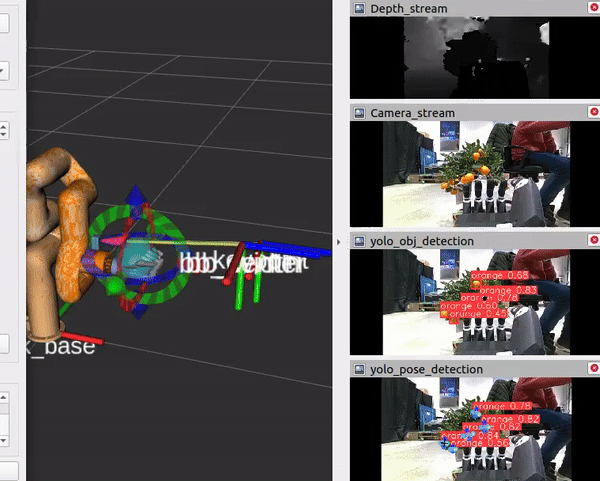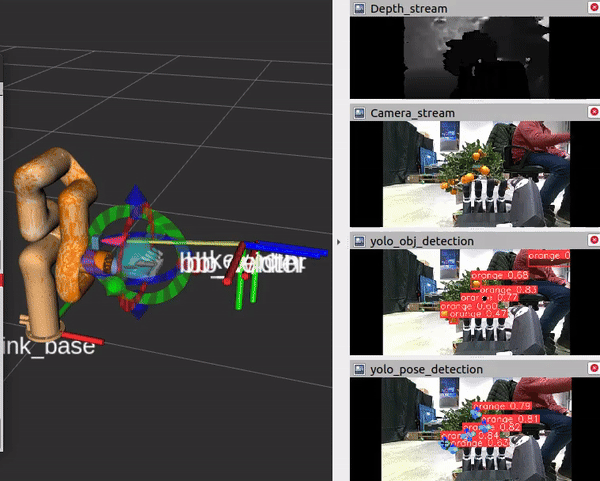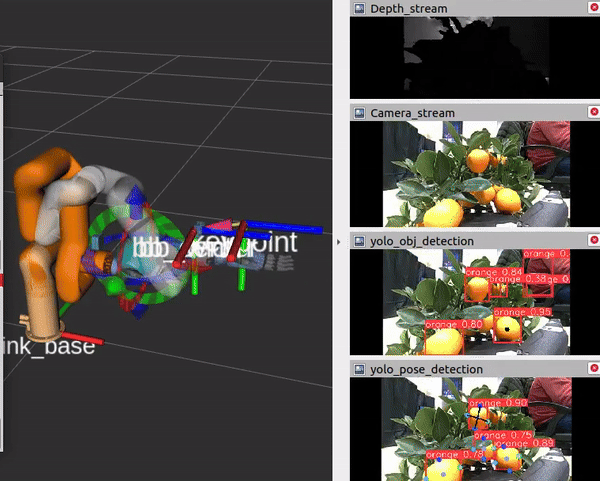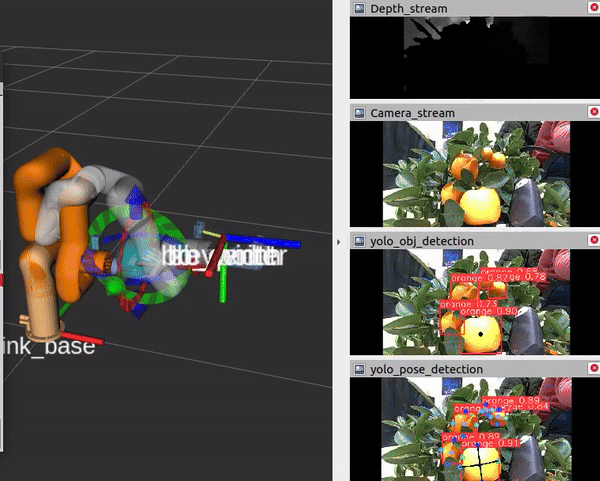
Camera view while performing orange grasping |
Following are the considerations and observations from the state-of-the-art works:
Deep NN models have been used extensively for vision-based solution.
The two-stage approach with vision model is followed with a depth camera, followed by motion planning with IK solution of joints.
The first stage performs object detection or instance/semantic segmentation to isolate the fruit from the background in the image.
The second stage involves point cloud processing or geometry manipulation techniques like estimating a sphere or frustum within a point cloud, etc. for estimating grasping pose. The data processing on a complete scene point cloud is not done.
The challenges with the two-stage vision-based solution for robot grasping are:
Training of two or multiple NNs, which requires considerable computation resources for training the network and on robot system.
Time investment on data preparation for multiple networks. Usually, the data annotation formats are different and objects have to be marked with bounding boxes or polygons on hundreds or thousands of images.
Pose estimation by simplifying geometrical estimation like with sphere fitting, which is not applicable with cylindrical or other shapes.
Relying on only one key feature information like stem for pumpkin grasping points estimation in [Ref.] and during occlusion scenarios, the estimations could not be processed properly.
The methodologies in the related works follow the steps to find out the grasping points or pose in multiple stages for a robotic arm, however, it can also be approximated by focusing on the information from multiple key features like stem, bottom, center, surface points, etc. on the fruit surface and detecting them. They can be used to estimate the grasping points or pose. Thus, a pose or key point estimation model can be a suitable model for the key feature or point detection. Recently, human-based pose estimation models have been deployed successfully with NNs [Ref.] . The idea can be employed and tested with the fruit grasping approach and thus, it will simplify the robot grasping task. The advantages of the key point-based approach would be:
Deployment of a single NN to get the grasping points, meaning lesser computations as compared with two stages of computations
Lesser time and effort investment in dataset preparation, as for two different networks data annotation in certain format must be prepared and it can be reduced.
Generalization for the fruit harvesting with robots. Some approaches used axis information for grasping pose estimation, nevertheless, every fruit has some unique points like center, stem, bottom, etc. that can be expanded to multiple domains.
RGB-D camera is used in almost all the related works. In some works, it has been attached near the end effector on the robot arm while some works have a fixed camera on the platform. The keypoint detection model would output the coordinates of the fruit points, similar to the center of bounding box coordinates for object detection models. The methodology would be somewhat similar to that of an object detection-based model, nonetheless, the model preparation approach and planning scheme steps are different.
An approach is built upon [Ref.] for the keypoint model due to the similarity with the object detection-related works methodology. The methodology takes RGB-D data as input from the camera node, which publishes them on a ROS topic. The key point detection node subscribes to the image topics and performs key point detection on the image. The depth information is then fused to obtain 3D coordinates of the key points and then published them. The goal position and the width information are extracted from the key points. The path for goal position is estimated with IK solvers in MoveIt for path planning. Once the plan is ready, the move group node of MoveIt makes the robot arm traverse to that point with the closing and opening of the gripper, the fruit is grabbed and then dropped at the fixed position.
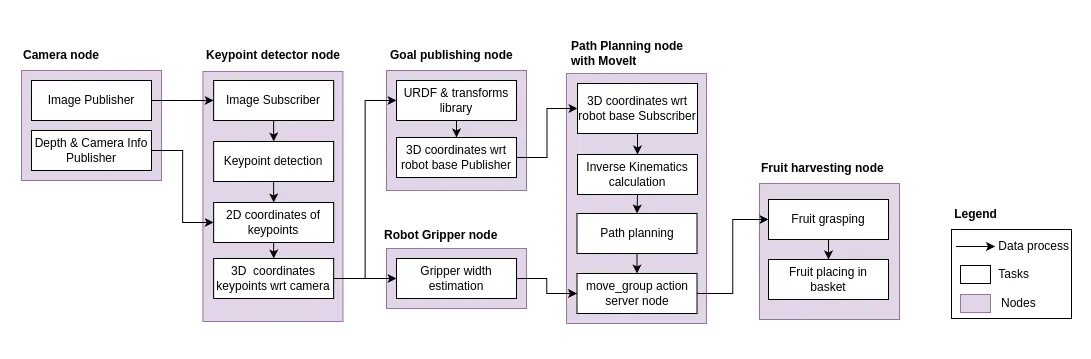
Figure: Research design
The key point detection task is a computer vision task to locate certain key features within an image [Ref.]. The key point detection has been in use in Augmented Reality, face matching, object detection, and so on. Machine Learning detectors like Scale Invariant Feature Transform (SIFT), Oriented FAST and Rotated BRIEF (ORB), etc have been used for matching object key points, however, DL-based models offer more flexibility [PP23] and they have been used successfully with human and animal pose detection [Ref.] . Some of them are intended for RGB image data and some for 3D point cloud data. On the other hand, pose detection models locate the key points in the body like joints, eyes, etc., and then connect them to output the pose of the body [Ref.] . Following are some of the state-of-the-art key point and pose detection models [Ref.], [Ref.] :
Mask R-CNN
CenterNet
Detectron2
Keypoint Detection and Feature Extraction for Point Cloud Registration(Kpsnet)
OpenPose
Simple Vision Transformer Baselines for Human Pose Estimation (ViT-Pose)
Key.Net
YOLOv8 (You Only Look Once version 8)
The models presented above are evaluated with a decision matrix to select the suitable one based on the following points:
Application feasibility: It tells whether the model could be used or adapted for fruits.
Ease of use: It tells whether the model possesses desirable parameters like high detection, ease of training, etc.
Custom tuning feasibility: It informs whether the training data for the model is available or the dataset size has to be large. Some works haven’t been shared publicly and it could impact the model selection.
Novelty: It tells whether the work has already been used in similar works related to fruit grasping.
Harvey Balls method [Ref.] h has been used to evaluate the models. A score value is assigned to each parameter and the model with the highest total score would be selected. It is a visual representation method to use balls for scoring a performance parameter and arrive at results. The three types of balls have been used to score the parameters:
A solid black ball represents that the parameter suits the requirement completely and has one point.
A half-black ball represents that the parameter might fit as the information is not available or not comparable with respect to other models and has a half point.
A solid white ball represents that the parameter doesn’t fit and has a score of zero.
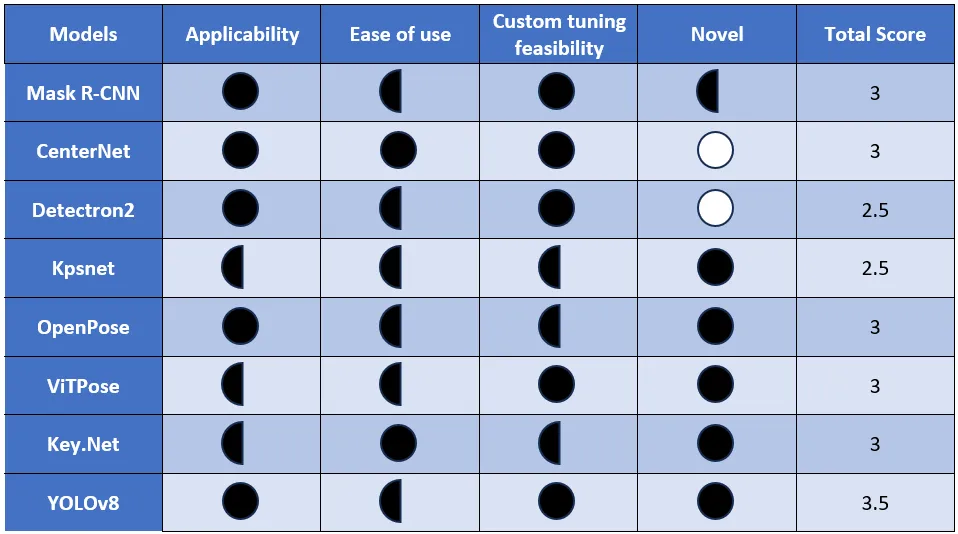 Figure: Evaluation of models based on Harvey balls visualization and
scoring
Figure: Evaluation of models based on Harvey balls visualization and
scoring
YOLOv8 pose estimation has the highest score and it turns out to be the suitable model, and the next section discusses and tries to understand the model in depth.
Robotic Vision
YOLOv8
YOLOv8 is a multipurpose NN model from Ultralytics [Ref.] and it offers object detection, segmentation, pose estimation, tracking, etc. YOLO series models are famous for their good detection speed and user-friendliness [Ref.] . YOLOv8 pose detects key points first and then associates them to human instances. There are mainly two types in the pose estimation model categories [Ref.]:
Top-down methods: These methods first detect the object and then detect the pose for each object using key points or features. On the one hand, these methods have high complexity and on the other hand, better accuracy.
Bottom-up methods: These methods detect the key points in a single stage, mostly by estimating the heat maps for the key points and relating them to the object via grouping. They are faster than top-down and, nevertheless, are comparatively less accurate.
YOLO-based pose estimation model falls in the category of the top-down method type of pose estimation model [Ref.] . The person is detected first and then the probability, bounding boxes, and key points are processed. The key features and observations related to YOLOv8 pose model are as follows:
The models are intended for humans with 17 key points and tiger pose estimation of 12 key points like eyes, nose, joints, etc. The skeletal structure output is enabled only for 17 key points input [Ref.] .
Only one class of object could be detected at a time. The modification for the class can be performed by providing encoding information in the yaml file.
There are six architectures for YOLOv8 pose estimation models [Ref.] : YOLOv8n-pose (nano), YOLOv8s-pose (small), YOLOv8m-pose (medium), YOLOv8l-pose (large), YOLOv8x-pose (extra large) and YOLOv8x-pose-p6 (extra large with an additional layer).
The model outputs a vector with x, y coordinates and confidence score or visibility for each key point.
The models are trained on the Common Objects in Context (COCO) pose dataset [Ref.] and COCO dataset format and YOLO pose annotation format are compatible.
Fruit Selection: One of the limiting factors in the model is single-class detection at a time, thus, a selection of fruit has to be made to proceed further and the orange fruit has been selected as the target fruit for the use case. A combination of public datasets along with the images captured by the camera has been selected for setting up the model for training. Some of the infested oranges are also considered for better training of the model. As the model is not originally intended for fruits, manual data annotation must be performed in either COCO keypoint or YOLO pose format. CVAT.ai [Ref.] is an open-source platform for data annotation and it offers multiple data format export options and the annotation format of COCO key points 1.0 format can be exported, which is converted to YOLO pose format before training [Ref.]. The following public datasets are used for preparing training and validation datasets:
Fruit Images for Object Detection: It is available on Kaggle [Ref.] and is segregated into train and test. It has images of apples, bananas, and oranges and has XML annotation files for object detection. It has varying images from oranges on a tree to oranges with a white background.
Roboflow datasets: Two datasets from the Roboflow platform have been taken [Ref.] [Ref.]. These datasets have around 140 images in total. In these datasets, the images of oranges on a tree and on the farm are present and damaged oranges with scabs and some with white backgrounds are also present.
Images from camera: The images with the camera for robot setup are considered and used for training to tune and deploy the model effectively with the camera settings for real harvesting tasks.
The goal is to detect orange from any configuration and keeping in mind the manual annotation part as well, around 180 images have been selected for training including images from the camera for robot setup and around 50 for validation. The five key points have been selected on fruit for the orange detection with YOLOv8 model: top, center, bottom, left, and right key points in orange.
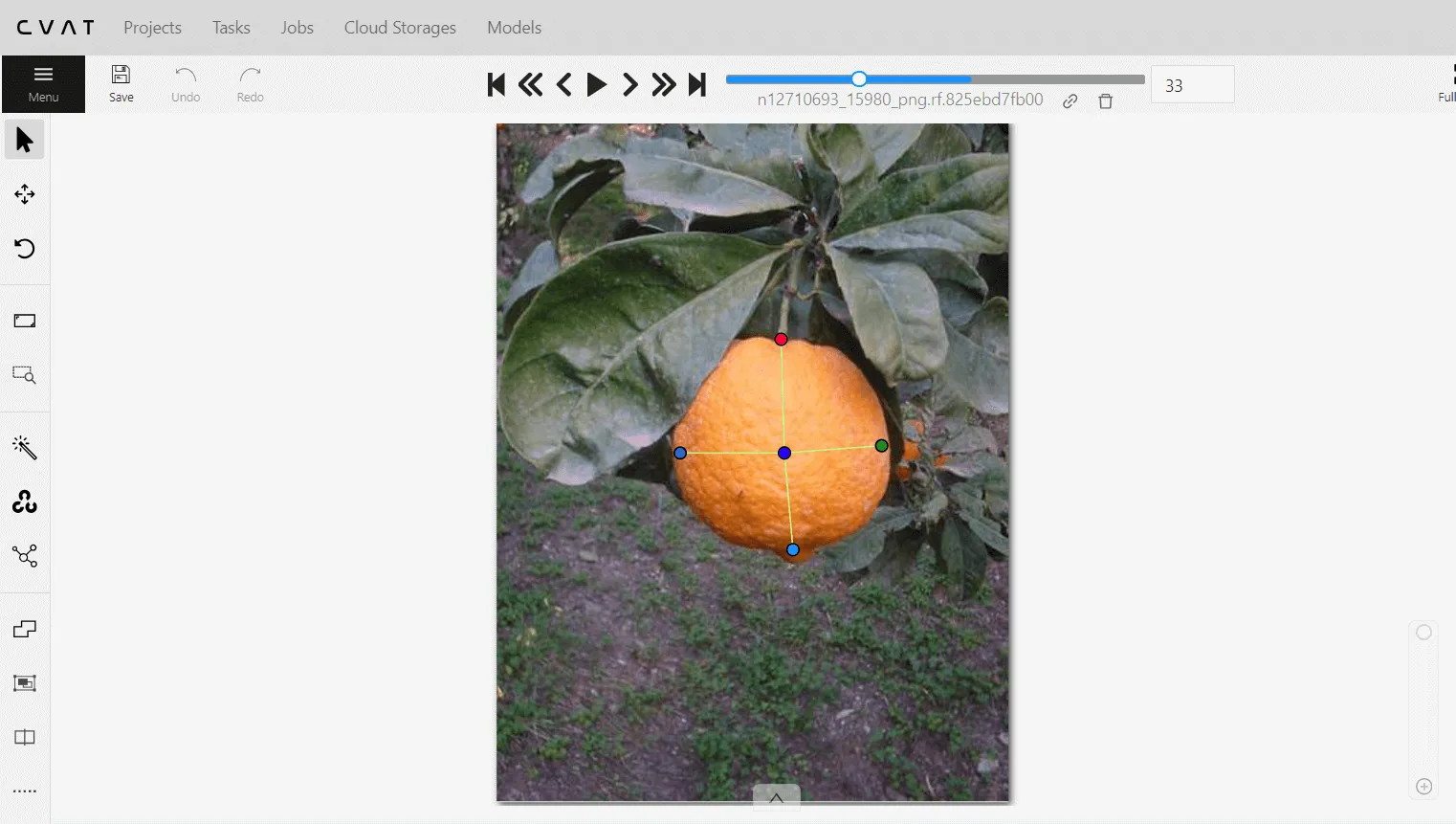
Data annotation on cvat.ai |
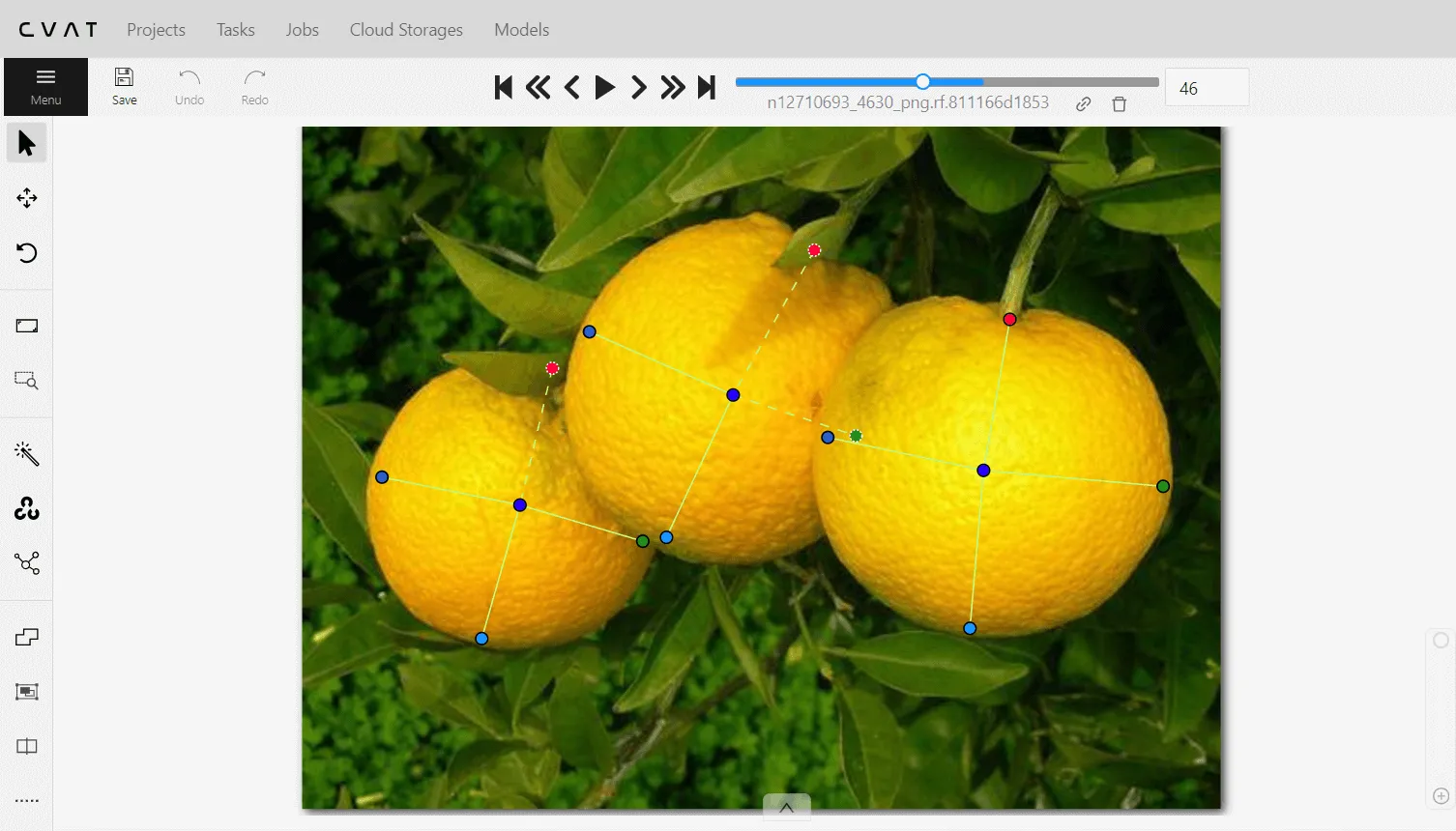
Data annotation on cvat.ai |

Key point detection with YOLOv8n-pose (nano) |

Key point detection with YOLOv8n-pose (nano) |
The losses have shown a decreasing trend and have reached convergence and the precision is high, meaning that out of the detections made by the trained model, the majority are accurate and similar, with recall, out of actual detections in the image, the majority are detected by the model.
The mean average precision for the model lies between 80% to 90%, and the detections on the sample images are acceptable for next steps. The larger weights can be considered for avoiding false detections and reliable results, however, with large weights, computation time would have increased. The system on the robot setup doesn’t have high-end computation resources, therefore, proceeding with nano weights.
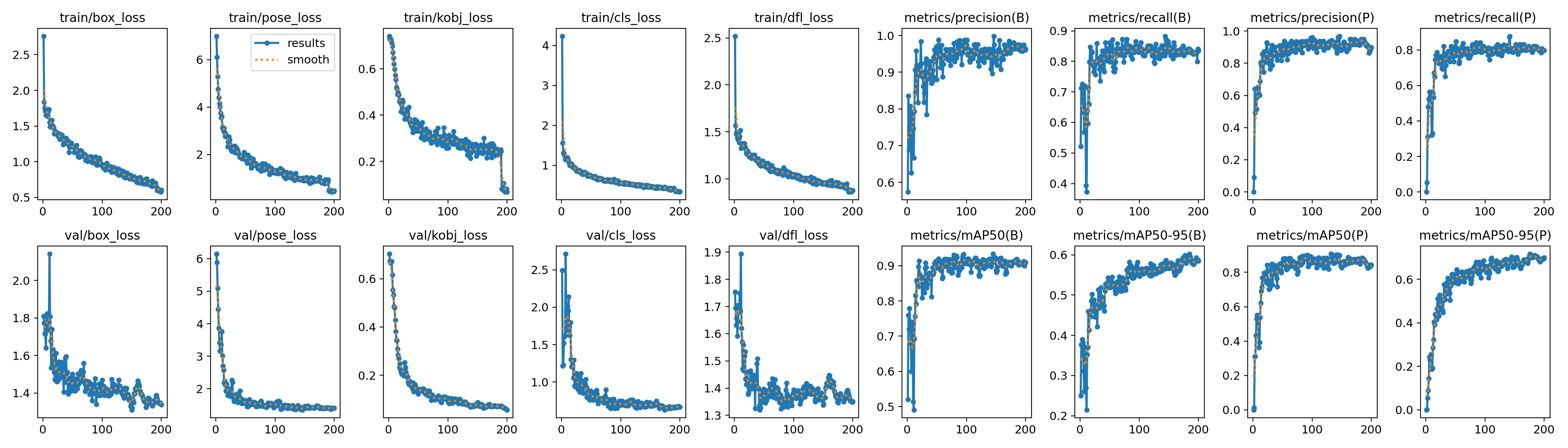 Figure: Performance of YOLOv8 pose nano model: Loss curves on
training and validation datasets showing convergence of losses.
Precision, recall curves reach close to annotated data.
Figure: Performance of YOLOv8 pose nano model: Loss curves on
training and validation datasets showing convergence of losses.
Precision, recall curves reach close to annotated data.
Vision Models
The YOLOv8 object detection model is selected as the baseline model for comparing the approach as the system doesn’t have Nvidia Graphics Processing Unit (GPU) and the computations are going to be performed on the system. The object detection model outputs the center of the bounding box and the YOLOv8 pose outputs the multiple key points along with the bounding box and is similar and two variants of YOLOv8: one with pre-trained weights and the other trained on a similar dataset of YOLO pose for 200 epochs. Three cases are going to be compared:
Fruit harvesting with YOLOv8 pose trained on custom dataset.
Fruit harvesting with YOLOv8 pre-trained model.
Fruit harvesting with YOLOv8 trained on custom dataset.
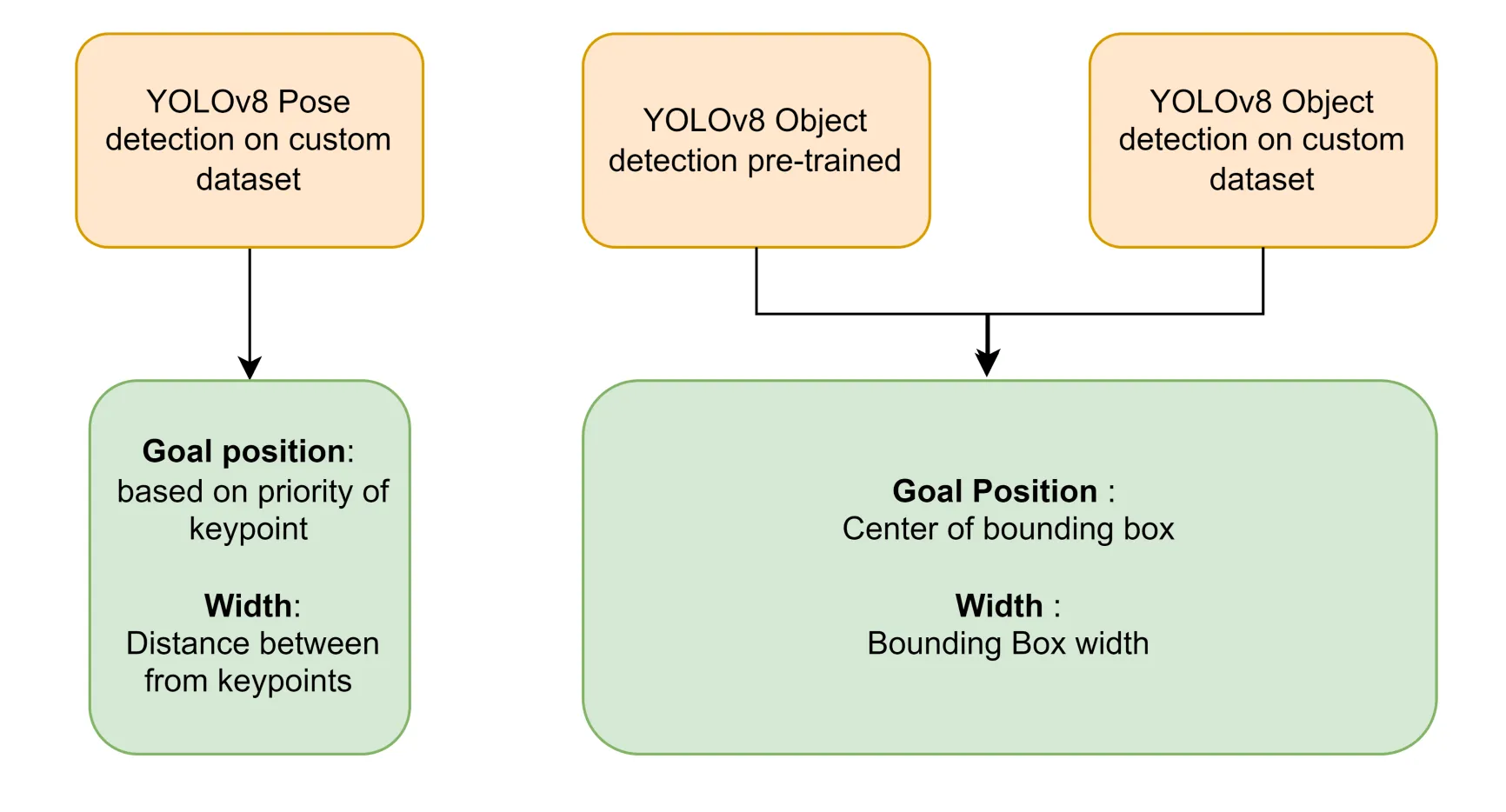 Figure: Comparison of goal position with baseline models.
Figure: Comparison of goal position with baseline models.
During fruit harvesting on a tree, fruits are usually adjoined or nearby to one another. Thus, a strategy has to be developed, when multiple fruits are detected. The higher detection probability rate lowers the risk of causing damage to robot setup and also achieves the task accurately. Thus, the priortization is given to high detection probability fruit for goal position for robot motion plan. The workflow has been shown in Figure below. When multiple detections are made by the YOLOv8 models:
The instance with a higher bounding box probability is selected first as the target. Either of the center and bottom key points must be visible and only these two key points are considered for goal position.
Based on the confidence values of bottom and center points with a threshold value of 0.5. One key point is selected in the proposed approach so that there is a good confidence score for the goal position. The center of bounding boxes for YOLOv8 object detection models are selected.
The shape estimation with YOLOv8 pose model is performed with average of distances between the key points or width or diameter estimation. On the other hand, the bounding box width governs the opening of the gripper for YOLOv8 object detection models in the methodology.
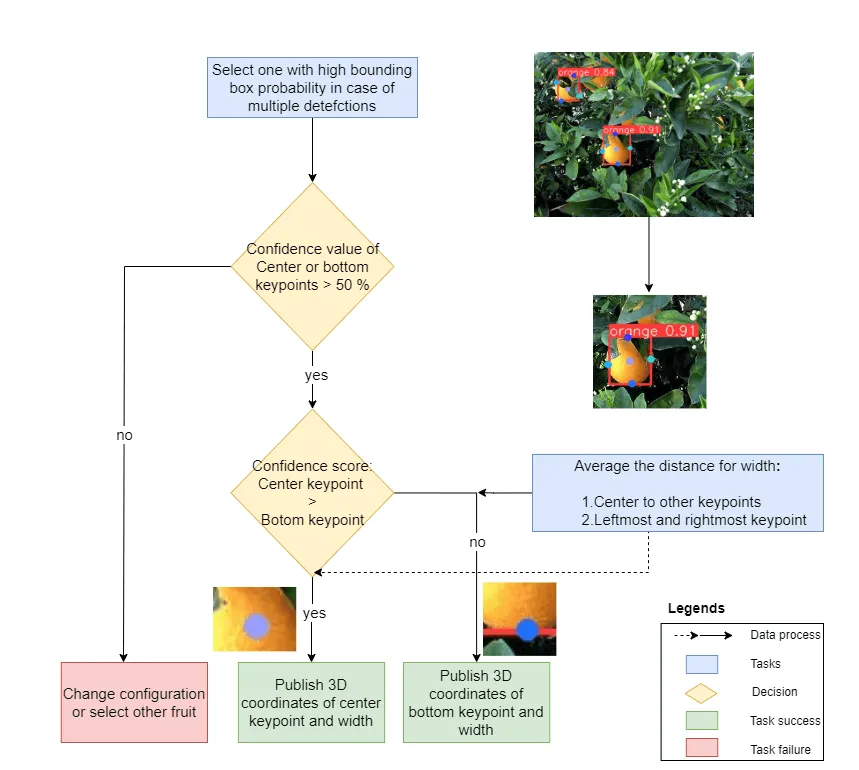 Figure: Multiple instances detection and goal position selection with
YOLOv8 pose.
Figure: Multiple instances detection and goal position selection with
YOLOv8 pose.
Methodology Flow
Once the fruit location and width are available, IK and motion planning is performed with MoveIt library in ROS. Considering the safety and ensuring the robot is ready and all systems are working, following is the action sequence:
Successful publishing of stabilized transforms for orange keypoint or bounding box center from the keypoint detection node.
Setting the robot to harvesting ready position of the arm with a fixed value of joints, picking pose, which indicates that the robot is ready for the grasping task. Changing of the position of target fruit or robotic setup if path planning fails to generate solutions.
Turning the gripper on or opening of the gripper.
Traversing to the goal position and attempting for a grasp by closing the gripper or suction with vacuum gripper. In case of a failed grasping attempt, two more trials are considered.
Moving the robot arm to fruit drop pose with another fixed joint pose near the collection spot, placing pose.
Opening the gripper to put the fruit in a basket or collector box.
Moving back to picking pose and turning the gripper off or close if the task is completed.
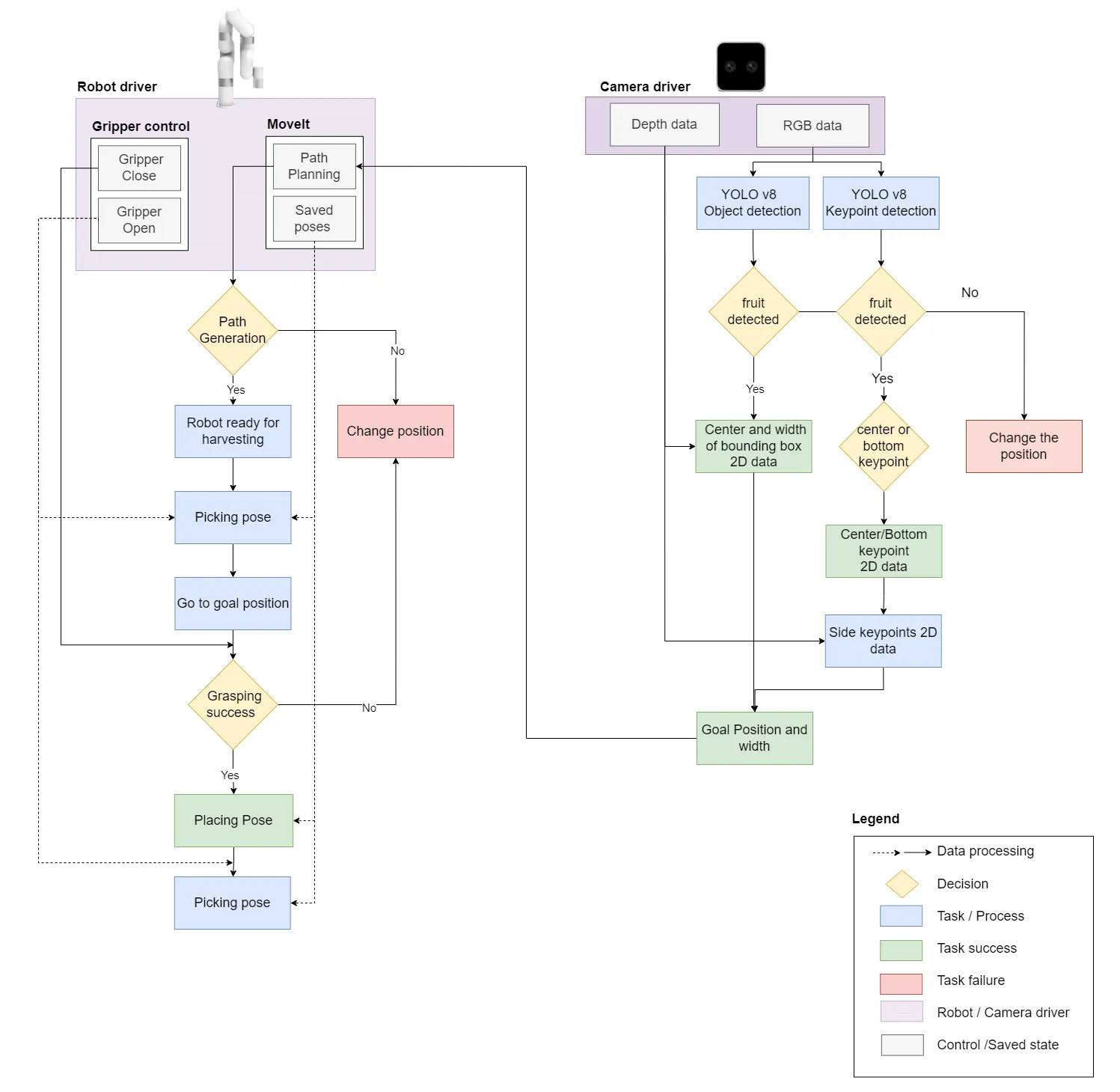 Figure: Pipeline for robot grasping planning with YOLOv8 pose and
object detection models.
Figure: Pipeline for robot grasping planning with YOLOv8 pose and
object detection models.
Robot Setup
The following components have been used and for testing:
Ufactory xArm5 robotic arm
Intel Realsense d405 depth camera
Inspire Robotics right hand gripper
xArm5 is a five DOF arm, which is manufactured by UFactory and its official catalog [Ref.] states that due to geometric constraints, the arm behaves like a four DOF arm while motion planning in some cases. Its reachability is limited to 0.7 metres and it can support a payload of up to three kilograms. The ROS drivers and software development kit of xArm5 are shared on github [Ref.] . Intel realsense d405 depth camera is a short-range stereo camera with a suitable range in between seven to fifty centimeters with depth, RGB, and point cloud information [Ref.] . Its ROS drivers and its model descriptions have been shared on GitHub [Ref.] and they will be used for integrating it with xArm5. The right hand gripper of Inspire Robotics has six DOF and it can support up to ten to fifteen Newton weight, which is approximately in between on e and two kilograms [Ref.] . the model description has been provided on its official website. The catalog describes twelve joints in the hand, with two per finger/thumb, and the joint motion is mimicked within a finger. Thus, the finger movement is controlled in one axis and the thumb can move around two axes. The technical specifications provide a brief glimpse about the capabilities and the challenges for integration and while performing the manipulation task. In summary, the combined setup has a workspace reachability of around 0.7 meters with limited four DOF for motion planning with IK solvers in space. The holding capacity of the fruit is limited by the finger load-bearing limit for safe operation. The suitable range for the camera and object detection task is within the workspace limits, however, it would not be covering the whole workspace, so the complete integration would answer how the system behaves as one.
Usecase Simulation
The github [Ref.] repository provides the URDF and the MoveIt packages and the specifications and the constraints are already added. However, the geometric constraints have limited its usage for autonomous operation. The trials were conducted with MoveIt and the Software Development Kit of xArm5 in Gazebo and on the real arm, nevertheless, the IK solvers could not solve the configuration for all the goal states. The following approaches were tried and tested:
Adjusting IK solvers: The MoveIt provides a multitude of solvers like Rapidly- exploring Random Trees (RRT), Bi-directional Transition-based Rapidly-exploring Random Trees (Bi-TRRT) in Open Motion Planning Library (OMPL), etc., and altering them have not solved the problem as they didn’t generate solutions for the goal poses in most of the cases.
Analytical solver plugin test: The IK-Fast plugin provided by MoveIt provides an option to integrate the solver which has to be run on either Docker or an older version of ROS. The analytical solver has failed in the Docker image and it has not generated solutions due to constraints in the geometry [Ref.] .
Approximation in joint space planning: A function was written and tested by excluding the first and last link of xArm5 as the other three joints move in one plane. The joint states would then be used to perform the arm movement along with the other two joints. The multiple solutions for the IK by this assumption and filtering them out is not a feasible option.
Addition of joint tolerances for IK solvers: By adding some tolerances in the goal configuration and using the position only IK, the solvers generate good solutions for almost all goal poses [Ref.] .
Cartesian path planning: The Cartesian planning approach takes the points as input and plans the motion to reach the goal configuration. Without the tolerances and position only IK, it could not generate good solutions. By splitting the goal position into x, y, and z points respectively positions with tolerances, the motion planning has worked fine.
The camera is mounted on the xArm5 last link with a bracket and it rotates along with the fifth joint of the arm. Extra tolerances are added in the box geometry for safe. operation during motion planning to ensure collision-free operation. The transform frame is added for the camera geometry with the addition in URDF, which would be used for the transformation of fruit with respect to the camera to fruit with respect to the robot base.
The d405 camera model is integrated into the URDF with the meshes for the visual tag and a box geometry is assumed for the collision to reduce the computation load. The gripper geometry is a combined model in STEP format and it is separated part by part in Fusion360 software to integrate the joints and movement of fingers and thumb for motion planning and grasping. In finger joints, joint rotation is mimicked for the fingertip if the finger base is rotated. The thumb can rotate on two axes, in one rotation, there are three joints mimicking the motion of the thumb base and for the other joint rotation, the whole thumb rotates.
The driver publisher is created in C++ and the joints and parts are added in the driver publisher for two joints per finger and four joints in the thumb and with the help of a mathematical function, the state from zero to thousand of the joints is converted to the angular values. The angles are then published on the joint states topic to perform movements and collision checks with MoveIt. The end effector point for motion planning is selected just above the palm so that the gripper should not collide with the orange while traversing. The complete setup, after integration of geometry and transforms, is tested with MoveIt planning interface with RViz plugin |
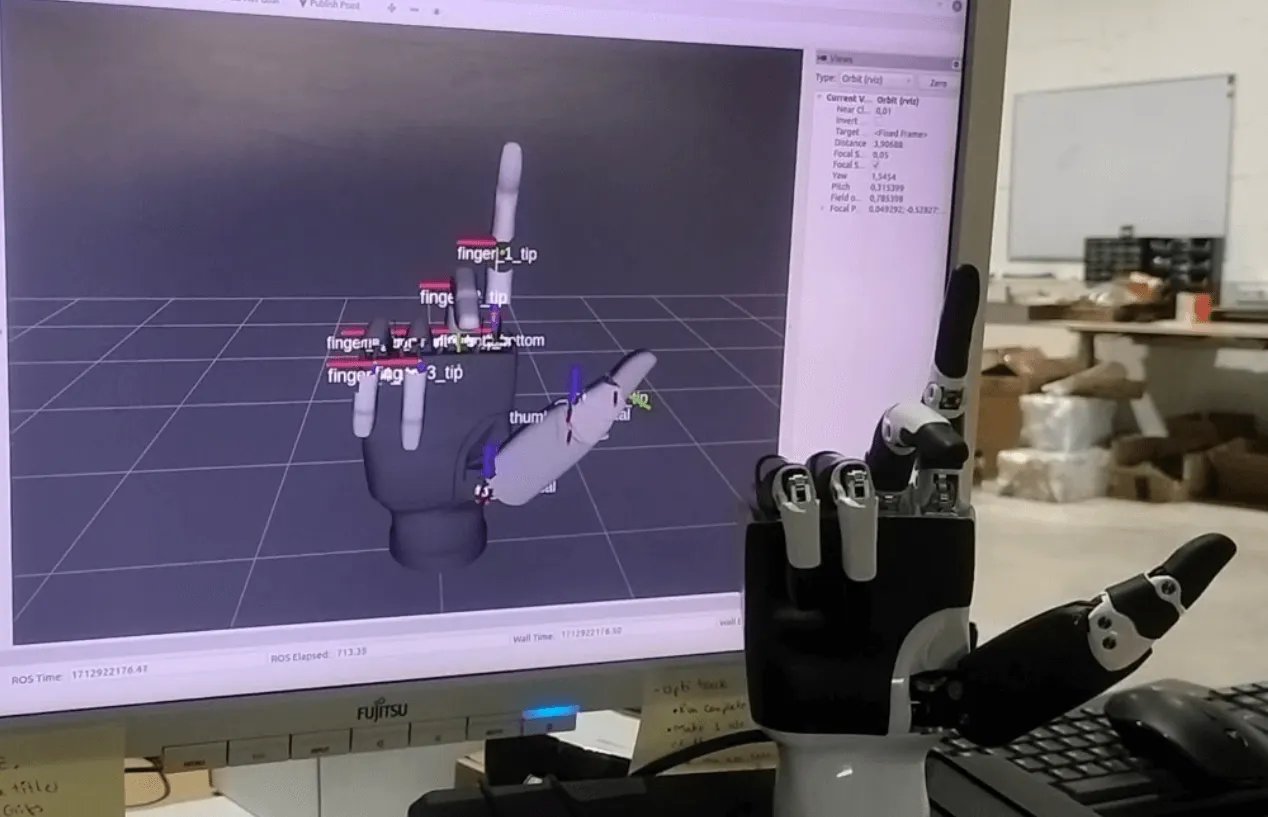
Gripper synchronization testing |
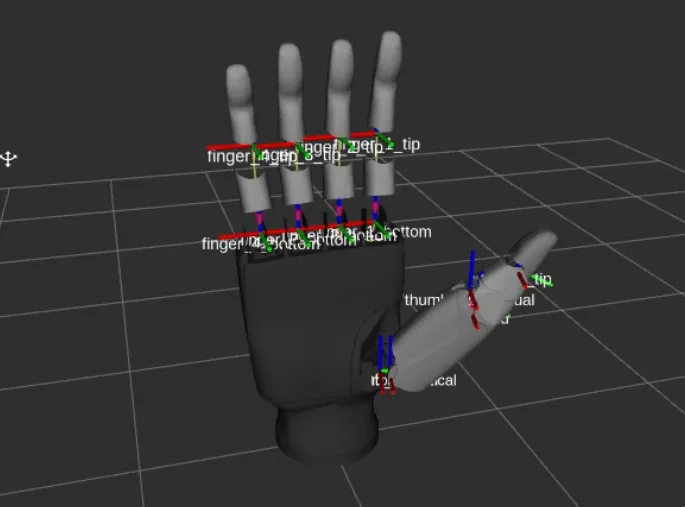
Visual geometry of gripper |
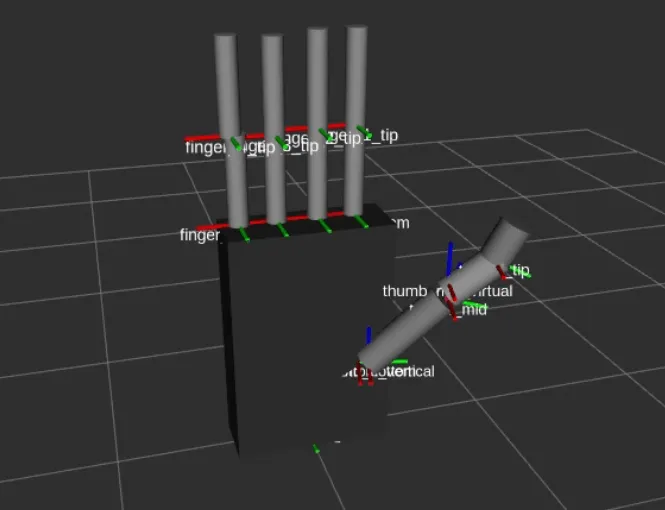
Collision geometry of gripper |
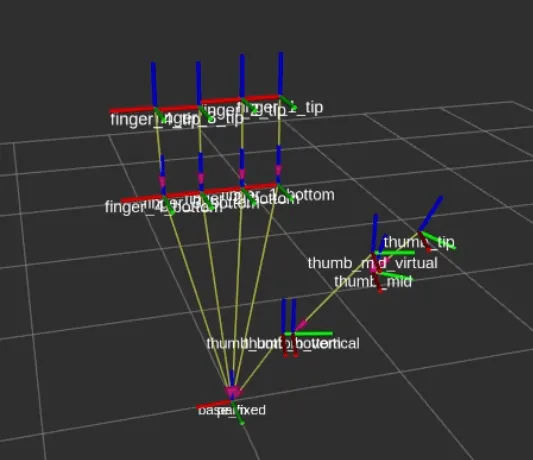
Transforms of gripper |

Visual geometry of robot setup |

Collision geometry of robot setup |
Usecase Hardware
Support:The robot setup is planned to be mounted on a mobile platform for outdoor testing and for safety considerations in indoor testing, the robot has been mounted for testing on horizontal fixed support.
Robot start pose and fruit dropping pose:A set of predefined positions is set for the fruit harvesting task. The picking pose is the ready state for fruit harvesting with the palm open and the last joint of the arm horizontal to the ground. The placing pose is the fruit-dropping state with the palm open and the last joint of the arm with 90 degrees rotation
Path planning method for goal position:Once the 3D transform frame of the fruit is published, the x,y, and z positions are split into three parts in the robot base coordinate system for the cartesian path planning method: x-axis displacement, y-axis displacement, and z-axis displacement. In Pose planning method, the Bi-TRRT planner of MoveIt has performed better during trials with planners and it is chosen for motion planning with tolerances to reach goal position autonomously. The cartesian planning method has been used for motion planning to avoid the dependency on the pose angles and the limited DOF due to the geometrical constraints of the arm.
Gripper closing control:The mathematical function to convert gripper opening in terms of angles is defined to control the closing of the gripper with the key points and bounding box width parameters. In case, there are errors in width transform publishing, the gripper is set to close to a half-closed closing configuration.

Picking ready state |

Fruit placing state |

Gripper grasping oranges of big size |

Gripper grasping oranges of small size |
Usecase Evaluation
The speed has been set low during trials to avoid any mishappenings and damage to the robot arm and other components. The cartesian planning method has been used for motion planning to avoid the dependency on the pose angles and the limited DOF due to the geometrical constraints of the arm. An average of 20 trials per model for each of the cases, i.e. 60 trials for each case for three models has been performed. In total, 180 trials have been conducted to evaluate the models while maintaining the same challenge or environment for all the models for each attempt.The performance of the approach has been evaluated in the following cases:
Orange grasping and placing without any occlusion.
Orange grasping and placing with occlusion.
Orange grasping and placing from a small plant.
Picking ready state |
Fruit placing state |
Gripper grasping oranges of big size |
Gripper grasping oranges of small size |
Following are the outcomes of the trials along with the analysis of the results:
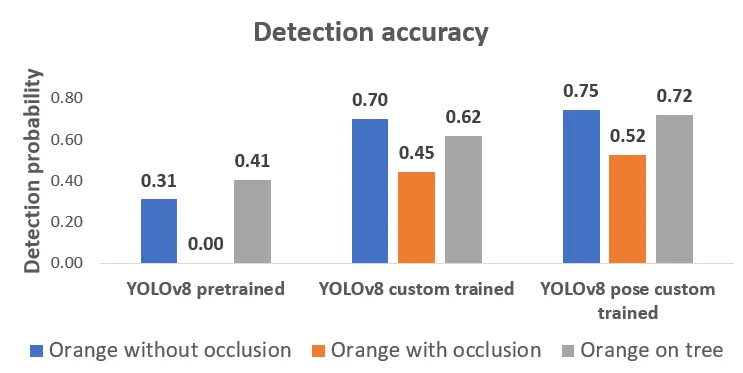
Pre-trained YOLOv8 model has performed poorly when it comes to detection accu racy and grasping attempts. The reason is that the Calamondin orange fruit has a smaller size when compared with other varieties of oranges. Whereas the custom- trained YOLOv8 object detection and pose model have performed better than the pre-trained model with YOLOv8 pose having higher detection rates. The overall detection accuracy with YOLOv8 pose averages more than 50% in the test cases including occlusion cases and five to seven percent higher than YOLOv8 custom- trained object detection model.
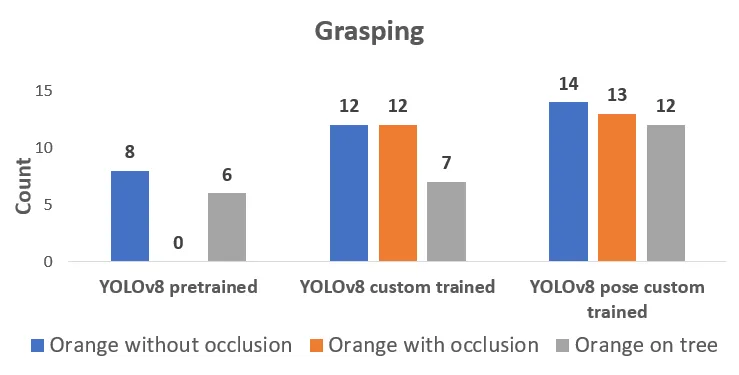
The successful grasping attempts with YOLOv8 pose have been the highest in each of the cases and YOLOv8 custom-trained is closer while performing the grasping. However, most of the time fruit has fallen off prematurely before reaching the placing pose with YOLOv8 custom-trained, thus, causing damage to the fruit. The fruit shape approximation is more accurate with YOLOv8 pose model.
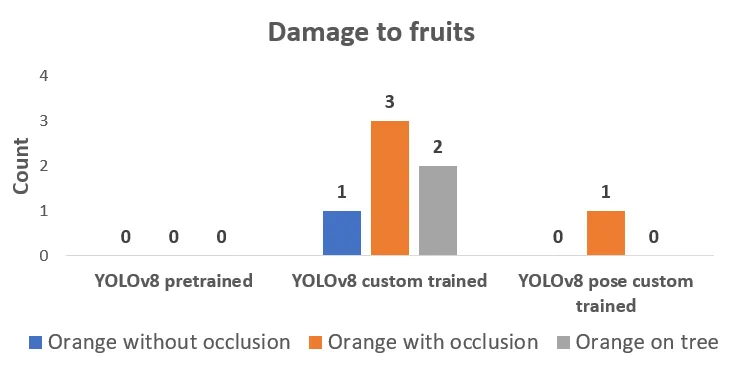
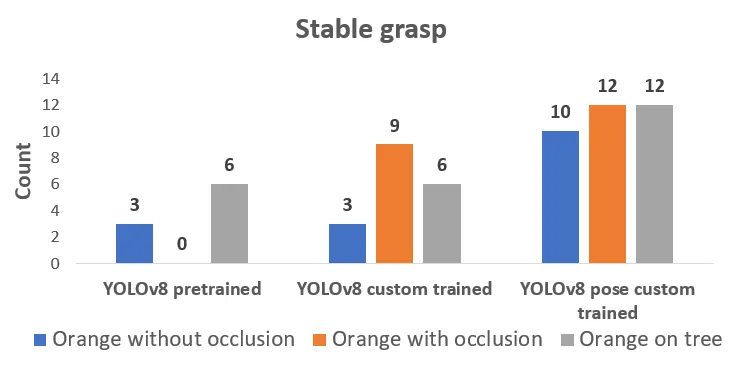
Custom trained YOLOv8 object detection model has performed better with occlusion cases with stable grasping than without occlusion cases, however, it has caused damage to the surrounding fruit as well. The higher stability of grasp is because of the less region visibility of orange, the smaller bounding box width of the box governs the opening of the gripper with a tighter grip, and the damage to fruits has increased.
The leaves and branches have presented obstructions in some cases during the fruit grasping and if the grasp is not stable, the fruit would either fall while plucking or be damaged. With the low detection rates with pre-trained YOLOv8 model, most of the time the detected fruit is located on the outer boundary of the plant, and hence, the damage cases to fruits are none.
The depth estimation of the camera on boundaries of the field of view, which is near the rectangular boundaries in the image and just outside the specified range of the camera, is not accurate. It has caused variations in the goal position and has impacted the path planning and stable grasping for all models.
For non-occlusion cases with YOLOv8 pose model near the rectangular boundary of the field of view, the width transforms have not published consistently, the gripper has switched to predefined closing value in the absence of width transform and it has resulted in unstable grasping. However, the fruit has been dropped in the box in some instances a bit earlier than the placing pose and it has been considered an unstable grasp.
The key point based methodology with YOLOv8 pose has shown:
Custom trained YOLOv8 pose is five to seven percent more accurate in terms of detection accuracy when compared with custom trained YOLOv8 object detection model.
The fruit grasping success when performed on the small plant is almost double when compared with object detection models.
The fruit shape approximation is better than with the bounding box-based approximations and it has caused lesser damage to fruits.
The harvesting success lies in the range of 60% and 70 % for the test cases in indoor cases. Whereas with object detection models, the harvesting success rate falls in between 30% and 60%.